

نویسنده: علی رجبزاده

نقش آمار توصیفی و استنباطی در تحلیل دادههای علوم اجتماعی
آمار ابزاری است که به پژوهشگران امکان میدهد دادهها را خلاصه کنند، ارتباط میان متغیرها را بسنجند و نتایج را از نمونه به کل جامعه تعمیم دهند. در علوم اجتماعی، آمار توصیفی و استنباطی نقشی حیاتی در تحلیل دادهها و فهم پدیدههای اجتماعی ایفا میکنند. این مقاله با تمرکز بر توضیح مختصر و کاربردی این دو شاخه از آمار، دانشجویان را با مفاهیم بنیادی آمار در پژوهشهای علوم اجتماعی آشنا میکند.
آمار توصیفی1 ابزاری است که به ما امکان میدهد دادهها را به شکلی منطقی و منظم توصیف کنیم. به عبارت دیگر، با استفاده از شاخصهای مرکزی و پراکندگی میتوانیم ویژگیهای اصلی یک جامعه آماری را بیان کنیم. برای مثال، محاسبه میانگین درآمد میتواند تصویری کلی از وضعیت اقتصادی یک جامعه ارائه دهد یا بررسی تأثیر سطح تحصیلات بر نحوه رأیدادن افراد، الگوهای رفتاری آنها را آشکار سازد.
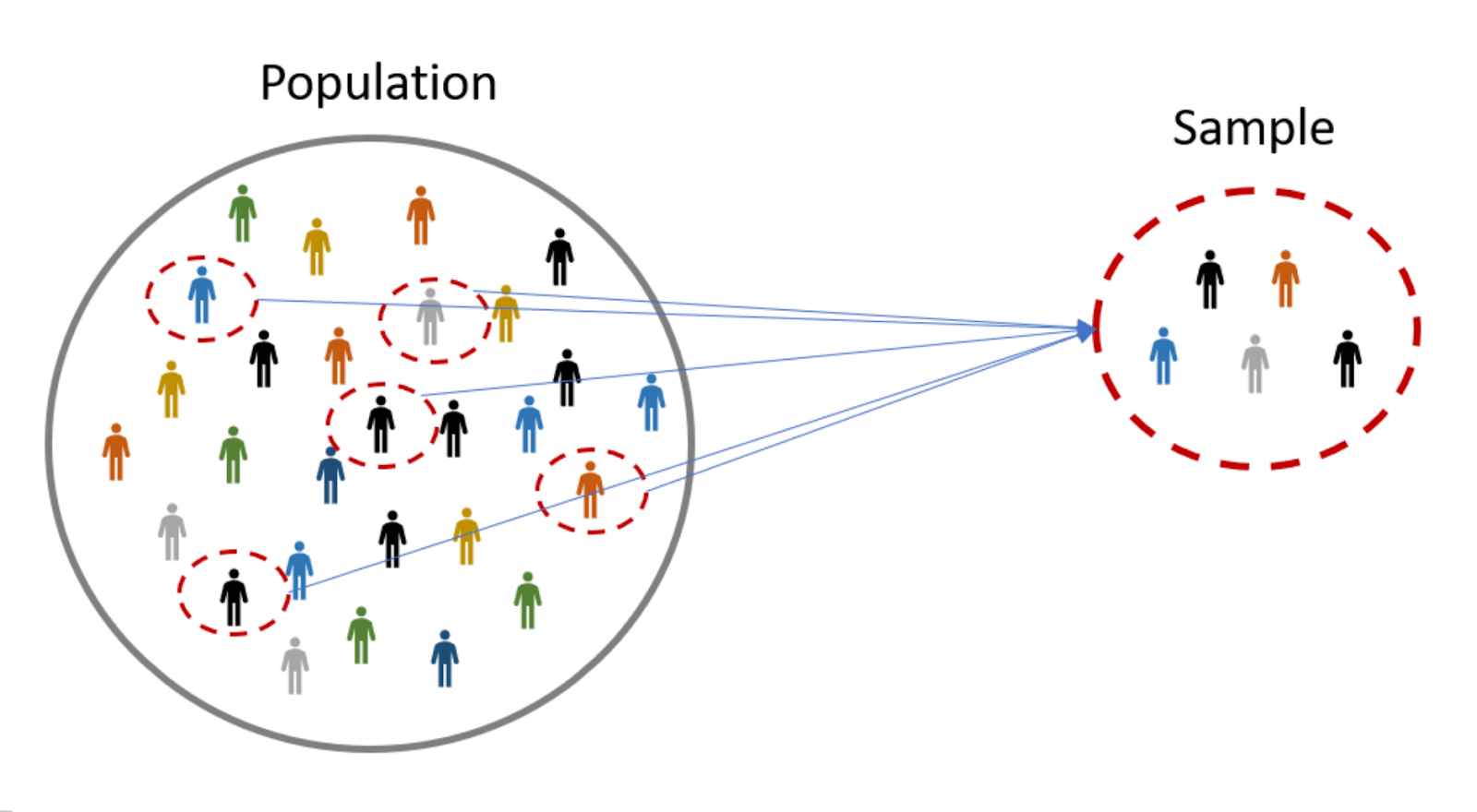
در مقابل، آمار استنباطی2 به پژوهشگران این امکان را میدهد که با مطالعه یک نمونه از جامعه، درباره ویژگیهای کل جامعه نتیجهگیری کنند. برای مثال، در پیشبینی نتایج انتخابات، با انتخاب یک نمونهی هزارنفری و پرسش از آنها درباره انتخابشان، میتوان با احتمال بالایی تخمین زد که کدام نامزد بیشترین شانس پیروزی را دارد. آمار استنباطی در واقع در پی «پیشبینی» یا «تفسیر» جامعه بر اساس دادههای نمونه است و نشان میدهد که نتایج بهدستآمده تا چه اندازه به واقعیتهای جامعه نزدیک هستند.
ترکیب آمار توصیفی و استنباطی به پژوهشگران این امکان را میدهد که ویژگیهای جامعه را بهدرستی تحلیل کرده و به نتایجی معتبر و قابل اعتماد دست یابند. این مقاله میکوشد تا با ارائه مفاهیم کلیدی و مثالهای کاربردی، دانشجویان را در مسیر درک و استفاده از آمار در تحقیقات علوم اجتماعی یاری رساند.
آمار توصیفی
در آمار توصیفی، با مفاهیمی از جمله میانگین، میانه و مد دست و پنجه نرم میکنیم که به شرح مختصر آنها خواهیم پرداخت؛
۱- میانگین: میانگین3، معیاری است که با تقسیم مجموع مقادیر بر تعداد آنها به دست میآید. بهعنوان مثال، اگر مجموع درآمد فارغالتحصیلان علوم انسانی در ایران را بر تعداد آنها تقسیم کنیم، به یک شاخص مرکزی دست مییابیم که میتواند به توصیف وضعیت کلی این جامعه آماری کمک کند. با داشتن میانگین، میتوانیم دیدگاهی کلی نسبت به کل دادهها به دست آوریم. در واقع، میانگین به نوعی نماینده تمامی دادههای ما محسوب میشود. البته این تنها ویژگی مثبت میانگین نیست؛ بسیاری از تکنیکها و تحلیلهای آماری به این شاخص مرکزی وابستهاند و از آن بهعنوان مبنایی برای ارزیابی و استنباط استفاده میکنند.
با وجود تمام جنبههای مثبت، میانگین از ضعف نیز مبرا نیست. یکی از مهمترین ضعفهای آن، تأثیرپذیری شدید از دادههای پرت4 است. برای مثال، تصور کنید در نمونهای از فارغالتحصیلان علوم انسانی، درآمد اکثر افراد حدود ۲۰ میلیون تومان باشد، اما یک نفر با درآمد ۲۰۰ میلیون تومان در این نمونه حضور داشته باشد. در چنین وضعیتی، اگر تنها به میانگین تکیه کنید، به نتیجهای نادرست خواهید رسید؛ چرا که میانگین به طور چشمگیری تحت تأثیر این داده پرت قرار میگیرد. به همین دلیل، در مجموعه دادههایی که توزیع نرمال ندارند، میانگین نمیتواند نماینده خوبی برای توصیف وضعیت کلی دادهها باشد و ممکن است نتایج را به بیراهه ببرد.
۲- میانه: اگر در مثال پیشین، درآمدها را از کم به زیاد مرتب کنیم، عددی که دقیقا در میان لیست قرار میگیرد همان «میانه5» است. برخلاف میانگین، میانه کمتر تحت تأثیر دادههای پرت یا چولگی6 قرار میگیرد. این ویژگی، میانه را به شاخصی مناسب برای مجموعههایی از دادهها تبدیل میکند که توزیع نرمال ندارند یا شامل مقادیر نامتعارف هستند. بهویژه در دادههای ترتیبی، میانه بهخوبی میتواند نماینده توزیع باشد.
در عین حال، میانه برخلاف میانگین، در بسیاری از تکنیکهای آماری بهکار نمیرود. با این حال، در برخی تحلیلها، بهویژه زمانی که دادهها نرمال نیستند یا حاوی دادههای پرتاند، میانه بسیار مفید است. روشهای آماری مقاوم7 از میانه و دیگر شاخصهای مقاوم استفاده میکنند، زیرا این شاخصها بهخوبی در برابر تأثیر دادههای پرت مقاوماند. علاوه بر میانه، «مد» نیز در تحلیل دادههای کیفی و اسمی کاربرد دارد و میتواند بهعنوان شاخصی مفید در تحلیل آماری دادههای دستهبندیشده مورد استفاده قرار گیرد.
۳- مد (Mode): «مد8» پرتکرارترین مقادیر را به سادگی نشان میدهد؛ درست همانطور که در زندگی روزمره چیزهایی که در میان دیگران پرتکرار هستند را «مد» مینامیم. یکی از ویژگیهای مثبت مد این است که میتوان از آن در دادههای کیفی استفاده کرد. به همین دلیل، در پژوهشهای افکار عمومی یا تحلیل بازار بسیار پرطرفدار است. با این حال، اگر مجموعه دادهها دارای چند مد باشد، دیگر بهعنوان یک معیار منحصربهفرد عمل نخواهد کرد.
نکته قابل توجه این است که، همانند میانه، مد در مراحل بعدی تحلیلهای آماری به کار نمیرود و ممکن است مرکز واقعی دادهها را نشان ندهد. همچنین، بسته به حجم نمونه یا نحوه دستهبندی دادهها، مد ممکن است اشکال مختلفی به خود بگیرد که بر تفسیر و تحلیل دادهها تأثیرگذار است. البته بر اساس اینکه دادهها یک یا چند مد دارند، اطلاعات ارزشمندی برای محقق فراهم میشود و همچنین در آزمونهای غیر پارامتریک کاربرد دارد.
آمار استنباطی
آمار استنباطی از سوی دیگر، در پی پیشبینی یا تفسیر جامعه بر اساس نمونه است. در آمار استنباطی، امکان تعمیم از نمونه به جامعه را داریم. با فرض اینکه نمونه، نماینده خوبی برای جامعه باشد، امکان تحلیل جامعه بر اساس تحلیل نمونه برای محقق فراهم است. همچنین یکی از کاربردهای آمار استنباطی، بررسی فرضیه و نظریههای موجود در علوم اجتماعی با روشهایی مثل آزمون فرضیه9، فاصله اطمینان و تحلیل رگرسیون وجود دارد.
با آمار توصیفی میتوان ویژگیهای نمونه را توضیح داد ولی سخن گفتن از علت و معلول مقدور نیست. اگر بخواهیم راجع به جامعه بزنیم و برای مثال نشان دهیم تحصیلات بیشتر با افزایش درآمد در کل جامعه همبستگی دارد، وارد قلمرو آمار استنباطی شدهایم. بنابراین، آمار توصیفی مربوط به مراحل اولیه تحقیق است و یک فهم و دانش کلی راجع به اینکه چطور باید از آمار استنباطی استفاده کرد، ارائه میکند. بینشهای حاصل از آمار توصیفی در انتخاب روش و رویکرد ما در آمار استنباطی بسیار موثر است. مثلا در صورت مشاهده چولگی در توزیع دادهها، سراغ تکنیکهای خاصی میرویم. پس، با ترکیب آمار توصیفی و استنباطی است که یک پژوهش کامل و معتبر شکل میگیرد و هر کدام به تنهایی ناقص هستند.
آزمون فرضیهها
برای ارزیابی اینکه آیا شواهد موجود در نمونه، از یک فرضیه راجع به جامعه حمایت میکنند یا نه، از آزمون فرضیه استفاده میشود. گام نخست، فرمولهکردن فرضیه است که شامل دو بخش میشود: فرض صفر10 و فرض جایگزین11. فرض صفر معمولاً بیانگر این است که هیچ تفاوت یا رابطهای وجود ندارد، در حالی که فرض جایگزین نشاندهنده وجود یک تفاوت یا رابطه است.
پس از تعیین فرضیهها، گام بعدی مشخصکردن سطح معناداری12 یا P-Value است. در علوم اجتماعی معمولاً از سطح 0.05 استفاده میشود (این عدد وحی منزل نیست بلکه بیشتر به یک توافق در جماعتی از محققان میماند)، که نشان میدهد اگر مقدار p کمتر از این عدد باشد، احتمال اینکه نتایج بهدستآمده ناشی از شانس یا تصادف باشند، بسیار پایین است. البته مقدار P-Value کوچک تنها شواهد قوی علیه فرضیه صفر فراهم میکند و بهتنهایی اندازه اثر13 یا اهمیت عملی نتایج را نشان نمیدهد؛ اما برای سادهسازی میتوان این طور تعبیر کرد که هرچه مقدار p کمتر باشد، شواهد در تایید فرضیه جایگزین قویتر است.
پس از جمعآوری دادهها، باید یک آزمون آماری مناسب برای محاسبه مقدار P انتخاب شود. در علوم اجتماعی، آزمونهایی مانند آنالیز واریانس (ANOVA) و آزمون T14 بهطور گسترده استفاده میشوند. این آزمونها به محقق کمک میکنند تا تفاوتها و روابط میان متغیرها را بررسی کند. به لطف نرمافزارهای آماری مانند SPSS یا R، انجام این آزمونها نسبتاً ساده است و تنها نیاز به درک مفاهیم پشت آنها دارد.
در ادامه، برای درک بهتر این مفاهیم، به ارائه یک مثال ساده از فرضیه و آزمون آماری در علوم اجتماعی میپردازیم:
فرض کنید میخواهیم بررسی کنیم که آیا تحصیلات بالاتر منجر به درآمد بیشتری میشود. فرض صفر این است که هیچ رابطهای بین تحصیلات و درآمد وجود ندارد (H0: تحصیلات تأثیری بر درآمد ندارد). فرض جایگزین این است که تحصیلات بر درآمد تأثیر میگذارد (H1: تحصیلات تأثیر مثبتی بر درآمد دارد). پس از جمعآوری دادههای لازم، با استفاده از آزمون T یا آنالیز واریانس میتوانیم مقدار P را محاسبه کنیم و ببینیم که آیا شواهد کافی برای رد فرض صفر و پذیرش فرض جایگزین وجود دارد یا خیر.
یک مثال از فرضیه و آزمون در علوم اجتماعی
فرضیه: میزان استفاده از شبکههای اجتماعی در میان نوجوانان، بیشتر از بزرگسالان است.
فرض صفر: در رابطه با میزان استفاده از شبکههای اجتماعی، تفاوتی میان نوجوانان و بزرگسالان وجود ندارد.
فرض جایگزین: میزان استفاده از شبکههای اجتماعی در میان نوجوانان، بیشتر است.
روش: جمع آوری داده از میزان استفاده در میان دو گروه و سپس انجام آزمون آماری متناسب.
تحلیل واریانس
تحلیل واریانس15، آزمونی آماری است که در علوم اجتماعی به منظور وجود یا عدم وجود یک تفاوت معنادار در میانگین سه یا چند گروه مستقل استفاده میشود. معمولا، زمانی از این آزمون استفاده میشود که یک متغیر مستقل کیفی با بیش از دو سطح(گروه) و یک متغیر وابسته پیوسته وجود داشته باشد.
یک مثال از تحلیل واریانس
تصور کنید یک پژوهشگر قصد دارد تا اثر سه نوع تراپی را بر کاهش میزان میانگین استرس بررسی کند. پس، سه گروه را با انتساب تصادفی تشکیل و هر گروه، یک نوع تراپی را در یک زمان واحد دریافت میکند و البته یک گروه هم به عنوان گروه کنترل، هیچ تراپی دریافت نمیکنند. سپس، رواندرمانگرها با یک آزمون معتبر، به میزان استرس شرکتکنندگان یک نمره عددی میدهند. حال، میانگین کاهش استرس برای هر گروه سنجیده میشود و نوبت به آزمون آنوا میرسد تا به محققان کمک کند. این آزمون به دو چیز نگاه میکند؛
۱- واریانس در میان هر گروه: میزان کاهش سطح استرس در میان افراد حاضر در هر گروه چقدر با یکدیگر تفاوت دارد.
۲- واریانس میان گروهها: میانگین کاهش استرس هر گروه چقدر با دیگر گروهها تفاوت دارد.
در نهایت، اگر آزمون نشاندهنده یک تفاوت معنادار میان گروههای دریافتکننده تراپی و گروه کنترل باشد، نتیجه میگیریم که حداقل یکی از روشهای تراپی نسبت به بقیه موثر تر است.
اندازه اثر چیست و چه اهمیتی دارد؟
اگرچه آزمون معناداری به محقق نشان میدهد آیا یافتهها و تفسیرش از دادهها واقعی هست، این معناداری بهتنهایی کافی نیست. مقدار P، به حجم نمونه بستگی دارد و با افزایش حجم نمونه، احتمال رسیدن به مقدار P معنادار را نیز افزایش میدهد اما معناداری به تنهایی، کافی نیست. در ادامه با ذکر یک مثال، تفاوت معناداری و اندازه اثر را نشان خواهم داد و خواهیم دید که اهمیت گزارش اندازه اثر در پژوهش چیست؟
تأثیر کمکهای خارجی بر توسعه دموکراتیک
سناریو:
پژوهشگران روابط بینالملل در حال بررسی این موضوع هستند که آیا کمکهای خارجی به توسعه دموکراتیک در کشورهای دریافتکننده کمک میکند یا خیر. آنها تمرکز خود را بر گروهی از کشورهای در حال توسعه طی یک دوره ۲۰ ساله معطوف کردهاند تا ارزیابی کنند که آیا افزایش کمکها با بهبود نهادها و شاخصهای دموکراتیک مانند انتخابات آزاد، استقلال قضایی و آزادی مطبوعات همبستگی دارد یا خیر.
یافتهها
- معناداری آماری: تحلیلها نشاندهنده رابطه آماری معنادار بین کمکهای خارجی و شاخصهای توسعه دموکراتیک است، بهطوریکه مقدار p-value کمتر از ۰.۰۵ گزارش شده است. این نتیجه به معنای آن است که احتمال اینکه همبستگی مشاهدهشده بر اساس تصادف باشد، بسیار کم است.
- اندازه اثر: اندازه اثر محاسبهشده نشان میدهد که با افزایش ۱۰ درصدی کمکهای خارجی، شاخصهای توسعه دموکراتیک ۰.۵ درصد بهبود مییابند.
تفسیر و اهمیت اندازه اثر
در حالی که معناداری آماری تأیید میکند که ارتباطی بین کمکهای خارجی و توسعه دموکراتیک وجود دارد، اندازه اثر نشاندهنده میزان واقعی این تأثیر است. بهبود ۰.۵ درصدی شاخصهای دموکراتیک در برابر افزایش ۱۰ درصدی کمکها نشان از تأثیر کم و نسبتاً ناچیز کمکهای خارجی بر تقویت دموکراسی دارد. این مسئله بیانگر این است که کمکهای خارجی بهتنهایی اثر قابلتوجهی در پیشبرد دموکراسی در کشورهای دریافتکننده ندارد. درصورت عدم توجه به مفهوم اندازه اثر، ممکن است پژوهشگر صرفا با توجه به آزمون معناداری از یافته تحقیق خرسند شده و چنین نتیجه بگیرد که میان کشورهایی که کمک خارجی دریافت میکنند و آنها که نمیکنند تفاوت معناداری وجود دارد؛ اما مسئله این است که اگرچه تفاوت معناداری وجود دارد، این تفاوت به قدری ناچیز است که گویی در عمل تفاوتی وجود ندارد. گاهی به جای اندازه اثر، از معناداری عملی نیز یاد میشود. برای محاسبه اندازه اثر، پژوهشگران معمولاً تفاوت میانگین یا ضریب همبستگی بین دو گروه یا دو متغیر را به دست آورده و سپس آن را بر انحراف معیار تقسیم میکنند. این روش باعث میشود تا تفاوت یا رابطه به صورت استاندارد بیان شده و امکان مقایسه نتایج میان مطالعات مختلف فراهم شود. اندازه اثر کوچک نشاندهنده رابطه یا تفاوت ضعیف است، در حالی که اندازه اثر بزرگ به معنای رابطه یا تفاوت قویتر است. با این حال، تعریف اینکه چه چیزی یک اندازه اثر کوچک یا بزرگ محسوب میشود، به حوزه و شرایط تحقیق بستگی دارد. اندازه اثر، معمولا با d کوهن16 یا ضریب پیرسون17 گزارش میشود.
نتیجه گیری
آمار توصیفی و استنباطی به طور بنیادی با یکدیگر در ارتباط هستند و هر کدام در حوزه تحقیق نقشی حیاتی و مکمل دیگری را بازی میکنند. آمار توصیفی به عنوان پایهای اولیه عمل میکند و خلاصهای روشن و موجز از دادهها ارائه میدهد. این نوع آمار با تشریح ویژگیهای کلیدی مانند تمایل مرکزی و تغییرپذیری(پراکندگی)، زمینهای را برای درک اولیه مجموعه دادهها فراهم میکند. این تحلیل ابتدایی بسیار مهم است زیرا میتواند جهت تحقیقات عمیقتر را هدایت و روشن کند. پس از بنا نهادن این پایهها، آمار استنباطی به میدان میآید و بر دوش این بینشهای اولیه میایستد. آمار استنباطی به محققان این توانایی را میدهد که بر اساس دادههای نمونه، دست به پیشبینی زنند، فرضیهها را آزمایش کنند و نتیجهگیریهایی داشته باشند که فراتر از دادههای ابتدایی، به جمعیت وسیعتری اشاره دارند. این پیشرفت از توصیف به استنتاج، در روششناسی اساسی است، زیرا به محققان اجازه میدهد تا ابتدا دادههای خود را درک کرده و سپس از آن درک برای استنتاج نتایجی با دامنهی وسیعتر استفاده کنند و در نهایت شکاف میان تحلیل دادهها و کاربرد در دنیای واقعی را پر کنند. مفاهیم و تکنیکهای تحلیل آماری بسیار پیچیده و گسترده هستند و در این نوشتار، به برخی از آنها اشاره شد.
منابع
Cetinkaya-Rundel, M., Diez, D., & Barr, C. (2019). OpenIntro Statistics. (Fourth Edition ed.) OpenIntro, Inc. https://www.openintro.org/book/os/
Freedman, D. (1998). Statistics.
Sirkin, R. M. (2006). Statistics for the Social Sciences. SAGE.
Field, A. (2013). Discovering Statistics Using IBM SPSS Statistics. SAGE Publications Limited. https://us.sagepub.com/en-us/nam/discovering-statistics-using-ibm-spss-statistics/bo%C3%B4k257672
- Descriptive Statistics ↩︎
- Inferential Statistics ↩︎
- Mean ↩︎
- Outliers ↩︎
- Median ↩︎
- Skewness ↩︎
- Robust Statistics ↩︎
- Mode ↩︎
- Hypothesis Testing ↩︎
- Null Hypothesis (H0) ↩︎
- Alternative Hypothesis (H1) ↩︎
- Significance Level ↩︎
- Effect Size ↩︎
- T-Test ↩︎
- Analysis of Variance ↩︎
- Cohen’s d ↩︎
- Pearson Correlation Coefficient ↩︎

